
Complete Guide on Azure Synapse & Power BI Integration
What is Synapse Analytics?
Azure Synapse Analytics is a limitless analytics service that brings together data integration, enterprise data warehousing and big data analytics. It gives you the freedom to query data on your terms, using either serverless or dedicated resources—at scale. Azure Synapse brings these worlds together with a unified experience to ingest, explore, prepare, manage and serve data for immediate BI and machine learning needs.
It is an integrated data platform services from Microsoft Azure combining the capabilities of data warehousing, integrations, ETL pipelines, analytics tools and services for big data capabilities, data insights, visualization and dashboards. For decision making standpoint it combines the analytical capabilities across all domains. As far as Descriptive and Diagnostic Analytics is concerned Synapse leveraging its Data Warehousing capabilities to generate business insights using T-SQL queries. For Descriptive and Prescriptive Analytics Capabilities it integrates with Apache Spark, Databricks and Stream Analytics.
What are the Synapse capabilities & its typical use cases?
Synapse capabilities
Synapse SQL – Dedicated pool of SQL Servers, backbone for the entire analytics storageServerless Model – Use data virtualization to unlock insights from underlying data sources without the need to go and setup a data warehouse. Main use cases are unplanned or adhoc workloads
Synapse Pipelines – it enables ETL and data integration capabilities
Apace Spark - It allows the development of big data workloads and machine learning solutions.
Synapse Link – Real-time operational analytics
Synapse Use cases
Data WarehouseDescriptive/Diagnostic Analytics
Realtime Analytics
Advanced Analytics
Reporting and Visualization
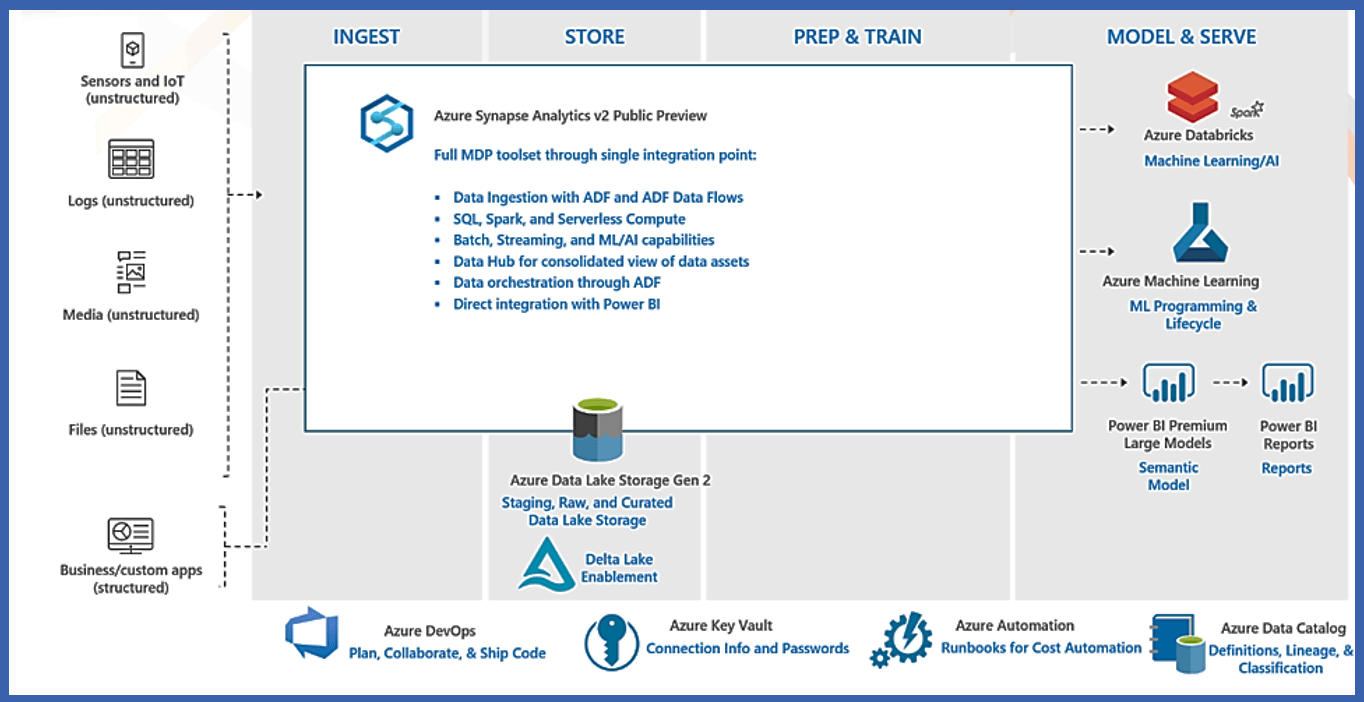
Symmetric Multiprocessing Massive Parallel Processing
Since Azure Synapse is based on MPP architecture thus it’s important to understand the difference between SMP vs MPP.
SMP
Symmetric Multiprocessing
Azure SQL Database (and traditional versions of SQL Server) utilizes computers based on the SMP model. it means that SQL Server is installed on a single computer/server that may (and probably does) have more than one CPU’s and cores and therefore permits parallel processing. However, there is only one database that is doing all the work to support requests. SMP (symmetric multiprocessing) is the processing of programs by multiple processors that share a common operating system and memory. A single copy of the operating system is in charge of all the processors. SMP, also known as a "shared everything" system, does not usually exceed 16 processors.
MPP
Massive Parallel Processing
The data warehouse provided in Azure Synapse Analytics is built on a Massively Parallel Processing architecture. Here multiple computers/servers (referred to as nodes) with dedicated processors are deployed, all with SQL Server installed. Each instance has its own processors, memory, and dedicated storage. Main node in this scenario is the control node. The purpose of the control node is to distribute requests to worker nodes. The worker nodes do all work that can be done locally and report the results to the control node. The control node then performs any additional work on the combined results from all worker nodes and reports the results to the requestor.
Azure Synapse Storage and Compute
Azure Storage is used for storage of your data in two scenarios.
Scenario 1
Dedicated SQL Pool
In this case once we load data into the Synapse table, it gets distributed across different compute nodes (depending on the type of distribution being chosen while creating table) and gets persisted in Azure Storage. This we called it as Dedicated SQL Pool.
Scenario 2
Serverless SQL Pool
In this case once we load data into the Synapse table, it gets distributed across different compute nodes (depending on the type of distribution being chosen while creating table) and gets persisted in Azure Storage. This we called it as Dedicated SQL Pool.
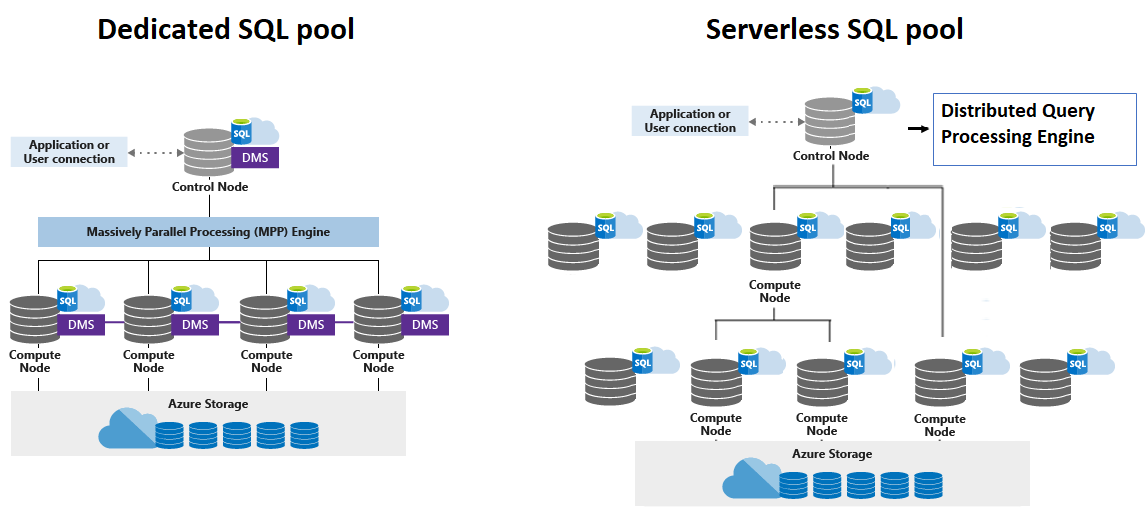
Control Node and Compute Node
To keep use data safe Synapse is using Azure Storage and separate charge is billed for storing and maintaining data by Azure Storage as part of the storage consumption. The Compute nodes also called worker nodes store all user data in Azure Storage and run queries in parallel. The Data Movement Service (DMS) is a system-level internal service responsible for moving data across the nodes as necessary to run queries in parallel and return accurate results.
Each control node has an instance of SQL Database for storage meta data, an MPP engine for distributed query optimization and processing along with coordination. This control node is responsible for managing and optimizing queries. When query execution request comes in this MPP engine on the control node creates a distribution execution plan by breaking down the query into parallel processes and coordinating that processing across multiple compute nodes running in parallel. Other than this control node also contains an instance of DMS (Data Management Service) whose job is to coordinating with all data movement taking place across nodes.
Based on the requirement we can have multiple compute/worker nodes. Each worked node contains instance of SQL database and does all the heavy lifting of executing query processes (assigned to them by the control node). Each node has its own set of local data which it's utilizing for query processing. Once processing is done send out the result to the control node.
After receiving the result from all compute nodes then control nodes aggregates the data and returns the final to the end-user who submitted the query for execution.
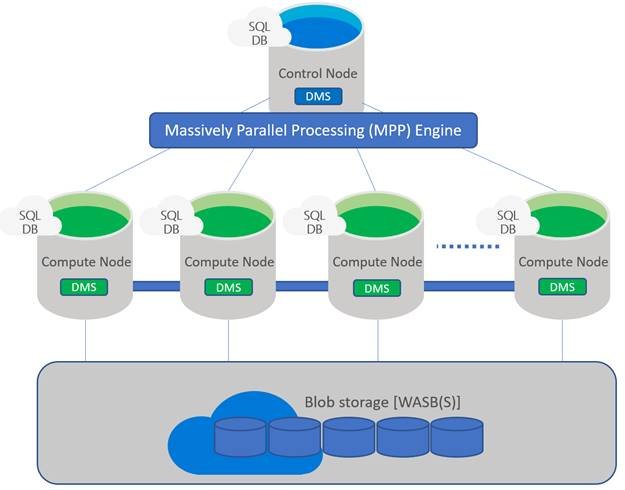
Data Movement Service (DMS)
Data Movement Service (DMS) facilitates communication and data transportation across nodes in the SQL Data Warehouse. The control node and each compute node runs an instance of Data Movement Service locally for coordinating data movement between the control node and compute nodes and between the compute nodes themselves, making it possible to distribute data on load and to perform joins and aggregations across multiple compute nodes during query execution.
Data Warehouse Unit(DWUs) - Scale of measurement
Computing Power in Synapse is measured in terms of data warehouse units(DWU) as unit of scale. Data Warehouse Unit (DWU) is a unit of measure of resources (CPU, memory and IOPS) that are assigned to Synapse. We can think of a unit as one virtual machine, working as one compute node. We can start with DW100 (one compute node) and can go up to DW6000 (60 compute nodes) to even DW30000 as well based on the need.
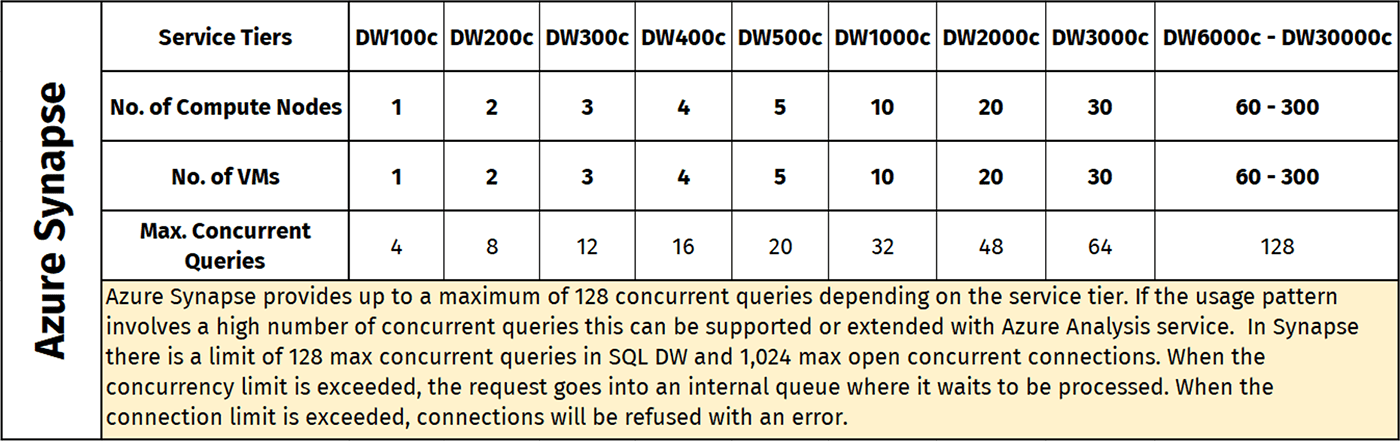
Main objective of DWU is to act as an abstraction layer to hide details of underlying hardware and software thus they can scale up or down without affecting workload performance. With this abstraction in place, Microsoft can adjust the underlying architecture of the service without affecting the performance of your workload.
Azure Synapse Analytics Engine
Azure Synapse is using two different types of compute or analytical engine - Synapse SQL and Spark. (not covering Apache Spark here)
Synapse analytics offers two different tools - Dedicated SQL Pools and Serverless SQL Pool. The former is used to work with Azure SQL Data warehouse, while the latter is aimed at providing analytics by using data directly from the data lake. Thus one can think of building physical (Dedicated SQL pool) as well as logical (Serverless SQL pool) data warehouse in Azure Synapse based on your needs.
Dedicated SQL pool allows you to query and ingest data from your data lake files
Serverless SQL pool allows you to query your data lake files
Dedicated SQL Pool (pay per DWU provisioned)
Dedicated SQL pool uses SQL Database(relational) and ADLS Gen2 as their main data sources.
Dedicated SQL pools, where you can provision a SQL pool at a unit of scale, scale the service up or down and pause it during non-operational hours
In Dedicated SQL pools compute power is determined by the provisioned unit of scale known as data warehouse units (DWU), and queries are distributed in parallel across compute nodes using a Massively Parallel Processing (MPP) engine
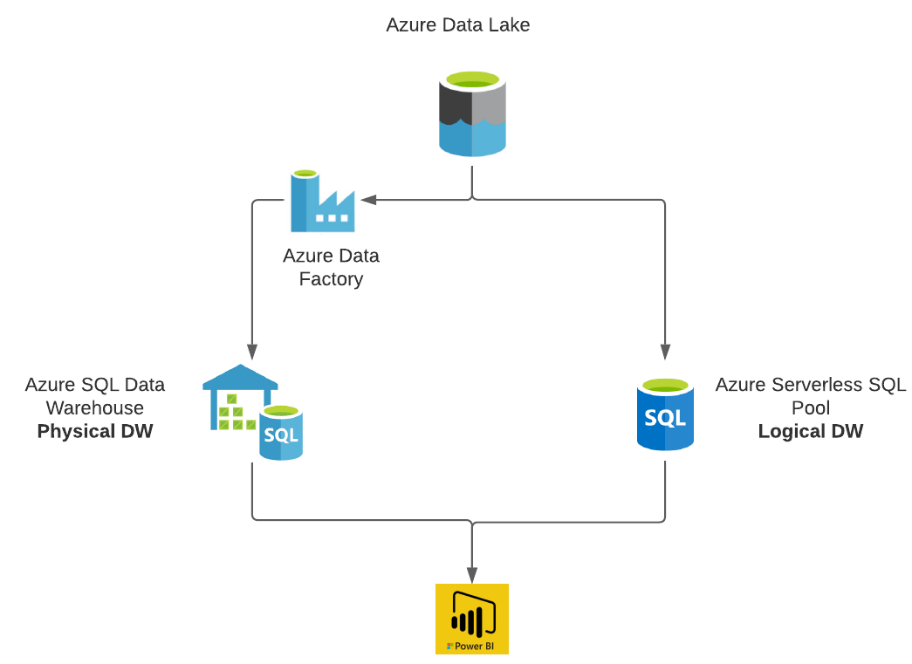
Serverless SQL Pool and Its Use Cases
Serverless SQL Pool
This is an auto-scale compute environment that uses T-SQL to query the data lake directly without the need to any data replication or staging the data. In this case data lake is used as the storage and Serverless SQL is being used as the computeIt is used as query as a service (QaaS) over data lake storage
Since it is Serverless, hence there's no infrastructure to setup or clusters to maintain. A default endpoint for this service is provided within every Azure Synapse workspace, so we can start querying data as soon as the synapse workspace is created
Here we don’t have to provision a server, it auto-scales and we consume the service on a pay-per-query cost model
Distributed Querying Processing (DQP) engine being used here that assigns tasks to compute nodes to finish the query execution
Number of compute nodes decided based on the number of tasks determined by DQP engine. This is what allows Serverless SQL Pool to scale automatically any query requirement.
Computation cost is based on per TB of data processed by the queries that we execute. Currently cost to process 1 TB of data is US 4.85$
With Serverless SQL Pool we can query data stored in ADLS Gen2, Azure Blob Storage, Cosmos DB
Use Cases of Serverless Pool
Explore and discover data in Azure Storage quickly and on-demandCreate a Logical data warehouse by creating transformation views in a metadata store for up to data, directly querying from your raw ADLS Gen2 (Data Lake) storage layer
Provide a relational abstraction on top of raw or disparate data without relocating and transforming data, allowing always up-to-date view of your data
a) Data Transformation - Simple, scalable, and performant way to transform data in the lake using T-SQL, so it can be fed to BI and other tools, or loaded into a relational data store (Synapse SQL databases, Azure SQL Database, etc.).
b) Build data visualization layers in Power BI, directly querying against Spark Tables.
Recommended Articles

The impact of Machine Learning in Next-Gen Business
Machine Learning (ML) and Artificial Intelligence (AI) are two buzz words popular amongst numerous industries such as finance, automobile, IT, etc. One common facet amongst all these industries is business.
Read More

How Organizations Leverage Advanced Automation and Machine Learning?
Machine Learning (ML) and advanced automation are some of the latest and the most trending words in the global business world. These advanced technologies have allowed companies to reimagine their working culture and combine digital intelligence into their system for enhanced end-to-end processes.
Read More

How is Data Science shaping the future of Modern Data Warehousing?
With evolving technologies and the growing complexity of business requirements, data has become more critical than ever. Data forms the backbone for all business decisions. In the years to come, data science will become a core factor in empowering business users and offering them greater autonomy in work by unleashing the power of modern data warehouses.
Read More
Contact Us
Decision Minds
Leaders in Cloud Analytics, Multi-Cloud deployments, Business Intelligence and Digital Engineering.
Interested in doing a project with us? We would love to hear from you.
Enquiries: sales@decisionminds.com
Careers: career@decisionminds.com
2150 N First St, Suite 446,
San Jose, CA 95131
Phone: (408) 940-5734
Fax: (408) 709-1830, sales@decisionminds.com
1205 BMC Drive, Ste.122,
Cedar Park, TX 78613
Unit No G03, Ground Floor,
C2 Block, Brigade Tech Gardens,
Brookfield, Bengaluru,
Karnataka - 560037